作者:CPDA数据分析师 刘云鹏
摘 要:在“移动互联网+”时代来临之际,切实开展真正的翻转课堂教学,将会开启大数据时代高等教育教学改革的新天地,每个教师都可以是自己课堂的大数据生产者。本研究通过移动学习环境下,开展云班课进行《动态网站设计》的混合式教学实践,并通过云班课收集的详细数据,利用“Datahoop”大数据分析平台,对学生的学习状况进行分类,分析学生的学习动机,探索基于网络的学生学习心理,为教师开展网络教学、制作满足学生需求的课程资源和学生考核管理办法等提供数据和理论支撑。
关键词:云教学;学情数据;教育数据分析;聚类分析
中图分类号:TP391.9 文献标志码:A
An Empirical Study of Learning Situation Data Analysis Based on Mobile Cloud Teaching Platform: A Case Study of Dynamic Website Design Course
Liuyunpeng
(Neusoft Institute Guangdong, Guangdong 528225, China)
Abstract: In the era of "mobile Internet +", to carry out the real flipped classroom teaching will open up a new world for the reform of higher education in the era of big data. Every teacher can be a big data producer in his classroom. This research carries out the mixed teaching practice of "Dynamic Website Design" in Blue Moyun Class under the mobile learning environment, and classifies the students'learning status, want to analyses their learning motivation and explores the students based on the network through the detailed data collected from the cloud class and the big data analysis platform of "Datahoop". Learning psychology provides data and theoretical support for teachers to carry out online teaching, make curriculum resources to meet students'needs and students' assessment management methods.
Keywords: Cloud Teaching; Learning Data; Educational Data Analysis; Cluster Analysis
一、前言
“大智移云”时代的高等教育,提高教育质量必然是重中之重。保证课堂教学质量、提升学生的综合素质更是教育信息化发展的核心目标。而教育领域的大数据研究,更应该追本溯源,努力在学科本位、知识本位、课程本位上利用大数据技术与方法,深度解析学生的课堂表现与学习效果,并分析学生的学习动机,从而产生积极的教育影响,帮助教师挖掘教学过程中潜在的影响因素,并加以针对性的改善。
二、研究方法
(一)教育大数据在学情方面的相关研究
2012年美国智库布鲁金斯研究院Darrell M. West最早提出,在教育领域中,可通过收集学生使用、互动信息,课程信息获取相关的教学数据如:分类(Systematic)数据、实时(Real-Time)数据、利用数据监管(Data Curation),高校行政部门可以获知相关教育管理信息,从而进行预测评估学校的各类教学信息,并通过数据可视化的方法,直观的显示给教育决策者以及教师,以便取得进一步的教育决策,最大化的监控学情。同年,美国教育部发布了《通过教育数据挖掘和学习分析促进教与学》(Enhancing Teaching and Learning through Educational Data Mining and Learning Analytics)提出了教育领域数据挖掘的四个范式目标,即:(1)开发学习者范式,通过对学习者的知识体系结构、学习动机、元认知、学习态度来构建范式,并预测学习者的学习状况及未来成绩。(2)开发相关课堂教学范式,最大化优化教学内容和教学方法。(3)开发各类教学软件运用范式,方便教育数据的采集。(4)综合考量学习者、课堂教学、软件运用等因素下,大数据时代的有效学习范式。
在以上范式目标下,教育大数据的研究主要可以采用以下几种方法Baker(2011)提出了:(1)趋势分析(Prediction)。通过历史数据进行多个变量的预测模式,如研究者通过在线学习环境中学习者参与在线讨论的情况 、 测试情况等,预测学习者在该门课程的学习中是否有失败的风险。(2)聚类分析(Clustering)。根据数据特性,将一个完整的数据集分成不同的子集 ,例如,研究者根据学习者在在线学习环境中学习困难 、交互模式等将学习者分成不同的群组,进而为不同的群组提供合适的学习资源和组织合适的学习活动。(3)关系挖掘(Relationship mining)。 探索数据集中各变量之间的相关关系,并将相关关系作为一条规则进行编码,例如,研究者利用关系挖掘,探索在线学习环境中学习者学习活动和学习成绩的相关关系,进而用于改进学习内容呈现方式和序列,以及在线教学方法。(4)自然语言转化(Distillation for human judgment)。用一种便于人类理解的方式描述数据,以便人们能够快速地判断和区分数据特征,该方法主要以可视化数据分析技术为主,用以改善机器学习模型。(5)模型构建(Discovery with models)。 通过对数据集的聚类 、相关关系挖掘等过程 ,构建供未来分析的有效现象解释模型。
Cristobal(2013)提出自适应学习和个性化学习将会成为一种新的学习范式,而数据对这种新范式的实践起着至关重要的作用。对于个性化教育,人们需要确定学生的相关数据,了解学习提升的真正要素,从而提供有针对性的教学。教育数据的挖掘,就是开发、研究和应用计算机方法从教育大数据中发现学习模式和特征,并且提出了数据挖掘的典型步骤包括:数据采集、数据预处理(如,数据“清理”)、数据挖掘和结果验证。机器智能学习系统可以保存人机交互所产生的详细日志,包括按键点击、眼动跟踪和视频数据。教育数据的挖掘即通过开发、研究并应用计算机智能化的方法,来检测教育大数据的模式。这些数据不仅包括学生个体与智能系统之间的交互数据(如,导向行为、互动练习等),也包括来自于学生之间的协作(如,文本聊天)、管理数据(如,学校管理、教师管理等)以及学生个体情况数据(如,性别、年龄、学校成绩、学习轨迹等)。学生的情感数据(如,动机、情绪状态等)是教育数据挖掘的重点,这些数据可以从生理传感(例如,面部表情、坐姿等)中推断出来。
基于以上的研究,本研究采用的方法主要是通过《动态网站设计》课堂教学实践中,依靠蓝墨云班课软件积累的自然教学数据,通过进行趋势分析、聚类分析等方法,进行学情分析。最后再通过数据可视化,解读学情背后的学生学习动机、学习心理。
(二)数据来源
结合教学实际,该数据选取的研究对象是16级的两个不同专业的本科班,每班人数约在30人左右,并通过同一学期的混合式翻转课堂教学实践。研究对象的课程成绩是由期末成绩+平时成绩两部分构成。总成绩=期末成绩×70%+平时成绩×30%。本研究的数据来源于蓝墨云班课教学的动态网站设计课程的两个教学班A班与B班,通过数据对比进行研究。
三、成绩趋势分析
参考国内外研究,结合独立学院“动态网站设计”的教学实际,课程团队构建了“动态网站设计”形成性评价方案。将“动态网站设计”学期成绩分为“平时考核成绩“与”期末考核成绩”两部分。比例为30%与70&。前者包含了六项活动分别为:非视频资源学习10%;签到10%;测试15%;讨论答疑5%;头脑风暴5%;投票问卷10%;作业/小组任务15% 课堂表现15%;被老师点赞加分5%。
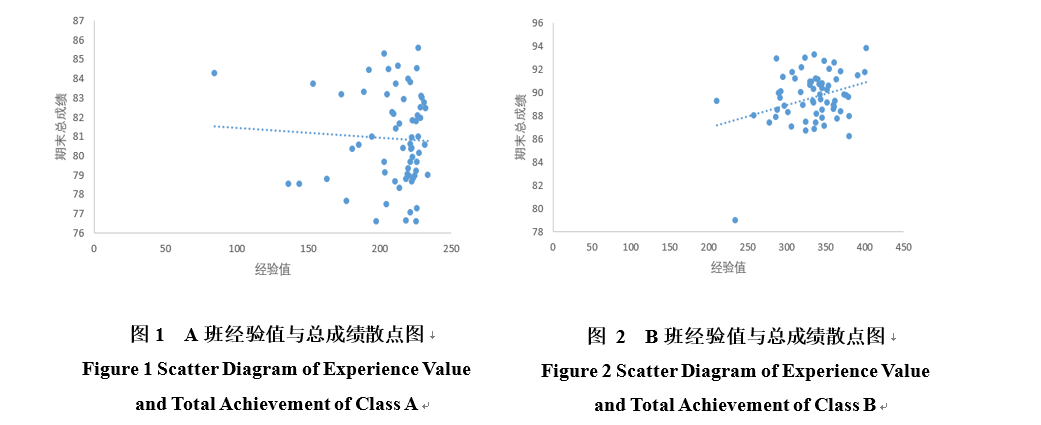
通过期末成绩分布表,我们可以看出A班的学生成绩与B班的学生成绩略有不同,A班成绩较为发散,B班成绩较为集中,为更进一步的研究A、B班的成绩分布,绘制散点图如图1 图2 通过绘制经验值为X轴,总成绩为Y轴的散点图可以清楚的看到两个班的成绩分布与经验值分布之间的关系状况,从散点分布来看,A班的经验值多集中在200-250之间,B班的集中在250-400之间,再从总成绩来看,A班经验值高的同学期末并不一定高,甚至呈现出经验值越高,总成绩越低的趋势,而B班则呈现出截然不同的趋势,经验值越高,期末总成绩也越高,并且成绩与经验值的分布程度更加集中。为研究这两种分布现象背后是什么原因造成的,有必要研究对两个班进行更进一步的研究。
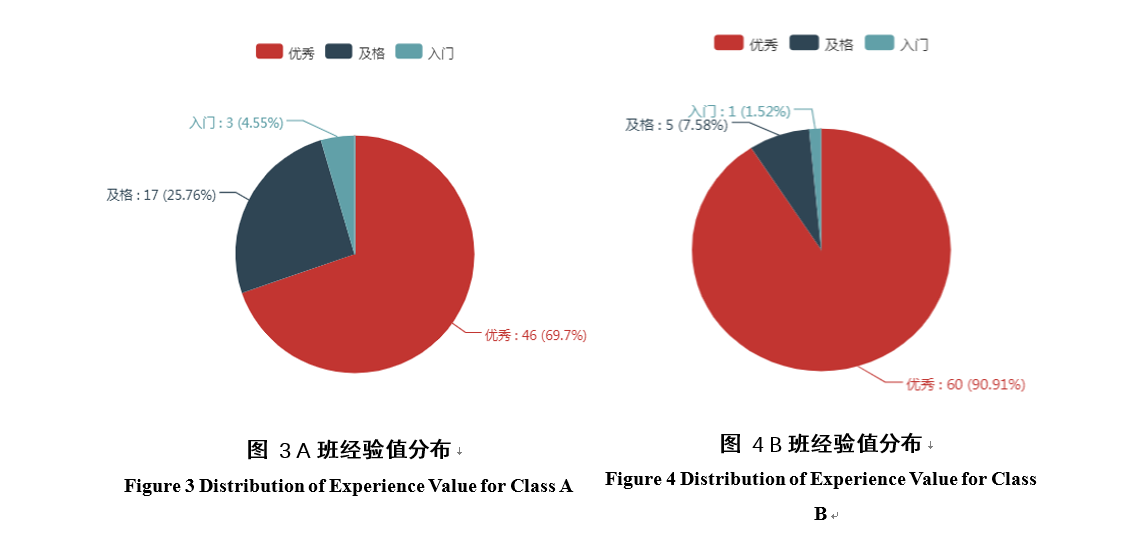
Table 1 Class a and class b performance distribution table
表1 A、B班成绩分布表
| 分数 |
A班人数 |
B班人数 |
| 100-90分 |
35 |
1 |
| 89-80分 |
29 |
40 |
| 79-70分 |
3 |
26 |
| 69-60分 |
1 |
5 |
| 59分及其以下 |
4 |
7 |
四、学情分析
为挖掘两个班的学情,利用蓝墨云班课导出的学情数据,需要选取有代表性的多个指标,通过聚类,尝试找到影响学生学习成绩的潜在因素。数据采集的经验值和期末成绩通过简单的回归分析,可以得到简单回归分析的两个教学班的指标如表2 所示,
Table 2 A, class b results distribution statistics
表2 A、B班成绩分布统计表
| 项目 |
A班 |
B班 |
| 回归方程 |
y=0.0194x+83.16 |
y=-0.0051x + 81.955 |
| R2 |
0.10 |
0.00 |
依据上表可以看出,建立线性回归方程无统计学意义。需要引入新的方法,也就是聚类法,本研究利用当下流行的大数据SAAS平台“DataHoop”来进行聚类测算,该平台的优势是内置丰富的数据分析和数据挖掘算法,能实现算法参数的自动调优和升级,同时包含了适合中国国情的行业应用模型。首先利用蓝墨云班课导出的学情数据可以看出课堂经验值的构成主要如下表所示。
Table 3 A, b class experience value itemized list
表3 A、B班经验值分项列表
| 项目
名称 |
非视频资源学习 |
签到 |
测试 |
讨论
答疑 |
头脑
风暴 |
投票
问卷 |
作业/小组任务 |
课堂表现 |
被老师点赞 |
| 比例 |
10% |
10% |
15% |
5% |
5% |
10% |
15% |
15% |
5% |
Table 4 A, class b phase empirical values are divided into correlation matrix
表4 A、B班相经验值分相关系阵
|
头脑风暴 |
讨论答疑 |
同学点赞总经验值 |
被老师点赞经验值 |
课堂
表现 |
非视频资源学习 |
课堂测验得分 |
| 头脑风暴 |
1 |
0.8694 |
0.5537 |
0.9362 |
-0.0883 |
0.3177 |
0.6315 |
| 讨论答疑 |
0.8694 |
1 |
0.7293 |
0.9185 |
-0.1419 |
0.42 |
0.4523 |
| 同学点赞
总经验值 |
0.5537 |
0.7293 |
1 |
0.8111 |
-0.042 |
0.6865 |
0.3569 |
| 被老师点赞
经验值 |
0.9362 |
0.9185 |
0.8111 |
1 |
-0.0798 |
0.513 |
0.5942 |
| 课堂表现 |
-0.0883 |
-0.1419 |
-0.042 |
-0.0798 |
1 |
0.4565 |
0.0294 |
| 非视频
资源学习 |
0.3177 |
0.42 |
0.6865 |
0.513 |
0.4565 |
1 |
0.3483 |
| 课堂测验分 |
0.6315 |
0.4523 |
0.3569 |
0.5942 |
0.0294 |
0.3483 |
1 |
将A、B班的以上各指标数据直接上传至“DataHoop”,为检验各类分项后所隐含的含义,首先检查变量间的多重共线性,从而能避免结果错误。根据表4可以看出,通过测算相关矩阵,《动态网站设计》该门课程的课堂活动因素存在较高的多重共线性,通过该检验可以发现变量 “头脑风暴”与变量“被老师点赞总经验值”,“点赞总经验值”与变量“被老师点赞总经验值”等变量间存在较高的多重共线性,需要减少变量,并需要为找出下一步影响学业成绩的潜在变量之前进行因子分析,也就是对该数据集进行“降维”见图5
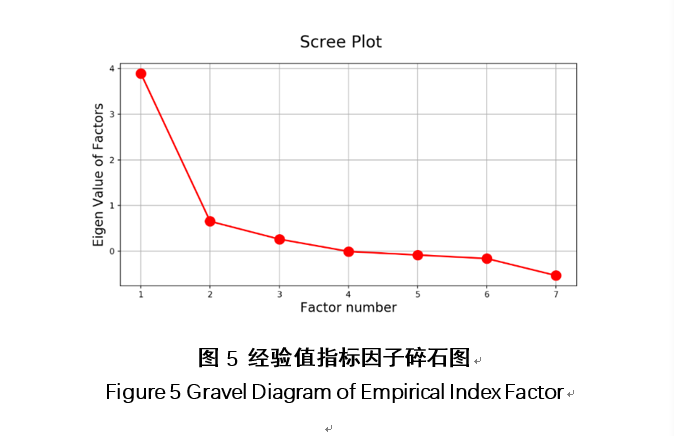
Table 5 Contribution Rate of New Variables Generated after Factor Transposition Matrix
表5 因子转置矩阵后产生的新的变量的贡献率
|
F_1 |
F_2 |
F_3 |
F_4 |
| 贡献率 |
0.5769 |
0.2131 |
0.5595 |
0.1335 |
| 累计贡献率 |
0.5769 |
0.79 |
0.5595 |
0.693 |
依据DataHoop检验报告(DataHoop可以在分析时默认进行标准化处理)表5可以看出,A班数据通过因子分析转置后产生的新的变量F1、F2贡献率分别为0.57与0.21 B班数据产生的新的变量F3、F4分别为0.56与0.13. 并对数据进行聚类分析,根据聚类结果分析每一类客户在现有变量上的特征,这里选取平均值作为参考依据。得到聚类分析描述结果为:
Table 6 correlation coefficient arrays (average profile coefficient is 0.67)
表6 A、B班相经验值分相关系阵 (平均轮廓系数为0.67)
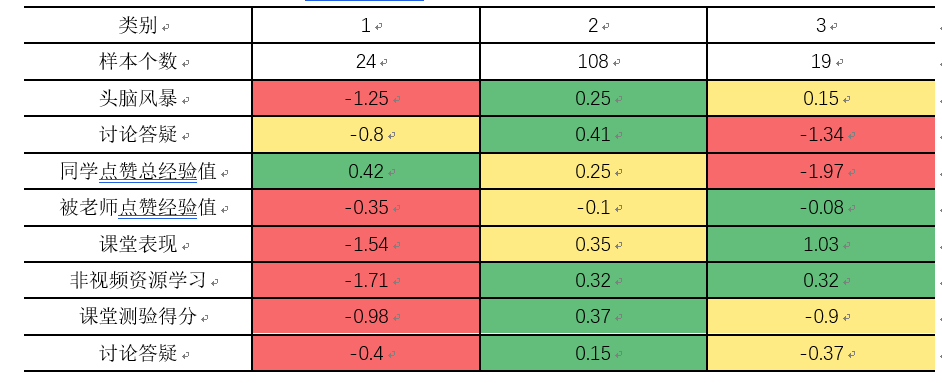
依赖于蓝墨云班课软件的数据,在当前成绩下,将两个班151名学生作为研究对象,我们在DataHoop上进行了K-means聚类分析,依据检验报告的结果, 可将学生依据课堂活动的指标,分为三类。研究结果如表6所示。
第一类学生,样本数24人,在课堂活动中,各项课堂活动得分均较其他两类学生更低,这部分学生课堂活动参与不积极,但 “同学点赞经验值”这项指标最高。 也可以认为在翻转课堂的教学场景下,开展的学生互评存在主观性,学生互评阶段的分数存在打“同情分”,打“感情分因素”的情况,由此可知,此项指标“点赞经验值”在该课程的学生互评过程中并不客观,需要教师设计合理的学生评价指标和统一规范的打分机制。
第二类学生,样本数108人,作为人数最多的类别,各项活动得分比较高,意味着翻转课堂的教学情境下大多数同学在实际教学中都能积极、按时的完成各项课堂活动,并达到考核标准。但由于人为主观因素,也可能造成经验值与成绩稍有偏差,但总体偏差不大。
第三类学生,样本数为19人,通过研究,可以发现该类学生在“讨论答疑”、和“同学点赞的经验值”这几项的得分都很低,但是在“课堂表现”、“非视频资源学习”与“被老师点赞的经验值”指标处,得分都很高。通过个案研究与访谈发现,该类同学属于“学习成绩优秀”的学生,在翻转课堂的学习中,应当充分发挥课堂中“榜样”的力量,并在课堂活动中增加 “答疑解惑”指标项的得分权重,鼓励更多同学,能积极主动的在学习过程中相互帮助,从而形成借助翻转课堂与移动云教学平台创建、积累、完善和分享知识的全新模式。
通过以上研究我们可以发现:在翻转课堂中,利用“蓝墨云班课”获得经验值与学习成绩并不直接相关,是由于经验值的获取来源较多,并且其中某些指标得分较为主观,不能直接用作平时成绩,或是经过加权处理后使用。另外翻转课堂中的教学评价,虽然可以参考“蓝墨云班课”软件设定的各种课堂活动作为评价指标,但其中的指标应当区分为“评价性指标”、“活动性指标” 以便在成绩评定时加以区分,使评价更加客观。
五、 结 语
大数据带给我们的是颠覆性观念转变:是所有数据,而不是随机采样;是主体方向,而不是个别精确;是关联关系,而不是因果关系。学情的分析,除了数据的分析及支撑外,还需要我们立体的,多角度的对学情分析结果的使用, 这样就能更有针对性的对学生进行个性化的教学。 我们的教育要让每一个学生都得到成长,以及感受学习的快乐。
基于蓝墨云班课 (Mosoteach) APP的深度学习, 以云平台应用优势作为技术支撑, 充分利用多种软件功能, 使教师、学习者、学习伙伴之间形成交互式的复杂关系, 并能为深度学习者提供多样化的丰富教学资源开展进阶式学习的多种途径, 使深度学习贯穿于课堂上下, 并为教师评价学习者、学习者自我评价或互相评价建立了通道。伴随整个深度学习过程, 产生一系列有益于促进深度学习的直观量化的追踪式评价数据。通过这一学习平台展开的设计谨严又能随机变化的深度学习过程, 能充分激发学习者的内在主动性, 使之以反思、质疑、批判的理性态度对新旧知识不断分析、整合, 促进学习者的表达、沟通, 不断进行新知识体系的建构和更新, 使深度学习得以持久延续。同时, 与真实世界相联系, 将所获理论知识迁移运用于解决实际生活问题。

 注意:CPDA数据分析师全国各地人才培养合作,请咨询13001995337王女士
注意:CPDA数据分析师全国各地人才培养合作,请咨询13001995337王女士

